
Si has recibido un email de Google Search Console con el asunto «Nuevos motivos que impiden que se indexen páginas en el sitio», significa que Google ha detectado URLs en tu web que no puede rastrear o incluir en su índice. No siempre es una emergencia, pero sí una señal que conviene analizar.
Acceso rápido
- 1 ¿Qué significa este aviso de Google Search Console?
- 2 ¿Dónde ver los motivos exactos en Search Console?
- 3 Todos los motivos que pueden aparecer en el informe de páginas
- 3.1 Descubierta: actualmente sin indexar
- 3.2 Rastreada: actualmente sin indexar
- 3.3 Duplicada: Google ha elegido una versión canónica diferente a la del usuario
- 3.4 Excluida por la etiqueta noindex
- 3.5 Bloqueada por robots.txt
- 3.6 Página alternativa con etiqueta canónica adecuada
- 3.7 Duplicada: el usuario no ha indicado ninguna versión canónica
- 3.8 Soft 404 o error suave
- 3.9 Error del servidor (5xx)
- 3.10 Redirección errónea o cadena de redirecciones
- 4 Cómo actuar ante este aviso paso a paso 🔍
- 5 Problemas de indexación e inteligencia artificial: una relación directa 🤖
¿Qué significa este aviso de Google Search Console?
Google Search Console envía esta notificación por correo electrónico cuando detecta, por primera vez o con más frecuencia de lo habitual, una serie de motivos técnicos o de contenido que impiden la indexación de determinadas páginas de tu sitio web.
Es importante entender desde el principio que recibir este aviso no implica necesariamente que tu web tenga un problema grave. En algunos casos, las páginas afectadas son exactamente las que tú has decidido excluir del índice de forma deliberada: páginas de administración, resultados de búsqueda interna, fichas de usuario o paginaciones. El problema real aparece cuando las páginas afectadas son aquellas en las que sí estás invirtiendo esfuerzo de posicionamiento.
Desde nuestra agencia SEO hemos comprobado en decenas de auditorías que muchos propietarios de web ignoran este aviso porque no saben interpretarlo. Ese error puede traducirse en semanas o meses de contenido publicado que Google simplemente no muestra en sus resultados.
¿Dónde ver los motivos exactos en Search Console?
El informe de indexación de páginas se encuentra en el menú lateral de Search Console, bajo la sección «Indexación» y después «Páginas». Ahí encontrarás dos bloques diferenciados que conviene entender bien.
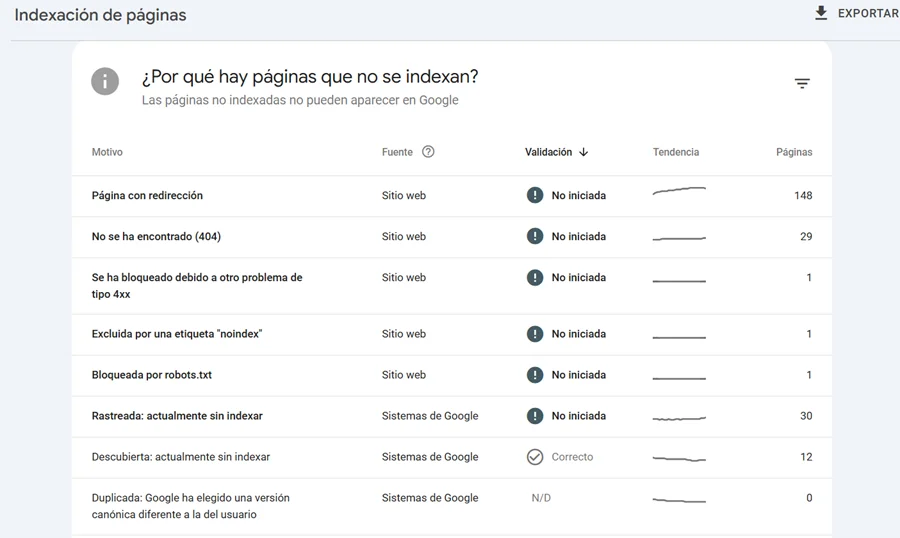
El primero, titulado «¿Por qué hay páginas que no se indexan?», muestra todos los motivos por los que Google no está incluyendo ciertas URLs en su índice. Cada motivo aparece acompañado del número de páginas afectadas y una columna llamada «Fuente», que puede indicar dos cosas muy distintas:
Si la fuente es «Sitio web», la exclusión proviene de una decisión técnica de tu propia web: una etiqueta noindex, un bloqueo en robots.txt o una etiqueta canonical. Puede ser intencionada o un error.
Si la fuente es «Sistemas de Google», ha sido el propio Google quien ha decidido no indexar esa URL, ya sea por considerar que el contenido tiene poco valor, porque es duplicado o porque el presupuesto de rastreo se ha agotado antes de llegar a ella.
El segundo bloque, «Mejorar el aspecto de una página», muestra problemas que no bloquean la indexación directamente pero sí afectan a cómo se muestra tu contenido en los resultados.
Todos los motivos que pueden aparecer en el informe de páginas
Descubierta: actualmente sin indexar
Este estado indica que Google ha encontrado tu URL (a través de un enlace interno, el sitemap o una referencia externa) pero ha decidido no rastrearla ni indexarla de momento. No es una penalización: simplemente, Googlebot la tiene en su lista de espera sin prioridad suficiente para procesarla.
Las causas más habituales son un presupuesto de rastreo mal gestionado, un dominio con baja autoridad o un exceso de páginas de escaso valor que Google considera que no merece visitar. Hemos desarrollado un artículo completo sobre este estado con todas sus causas y soluciones paso a paso: Descubierta: actualmente sin indexar.
Rastreada: actualmente sin indexar
Aquí Google sí ha visitado la página y ha leído su contenido, pero ha decidido de forma autónoma no incluirla en su índice. Es una decisión editorial del algoritmo basada en la calidad del contenido, su diferenciación respecto a otras páginas del sitio, la estructura de enlazado interno o la coherencia semántica general del dominio.
Con las últimas actualizaciones de Google relacionadas con el helpful content, este estado se ha vuelto especialmente relevante: el algoritmo es cada vez más exigente con qué contenido merece estar en su índice. Te explicamos en detalle todas las causas y cómo resolverlas en nuestro artículo: Rastreada: actualmente sin indexar.
Duplicada: Google ha elegido una versión canónica diferente a la del usuario
Este aviso aparece cuando has indicado mediante una etiqueta rel=canonical cuál debería ser la URL principal de una página, pero Google ha ignorado tu indicación y ha decidido indexar una versión diferente. Es importante entender que las etiquetas canonical funcionan como señales, no como órdenes: Google puede decidir no respetarlas si detecta incoherencias en el enlazado interno, en el sitemap o en la estructura del sitio.
Puedes consultar todas las causas y el proceso de corrección paso a paso en nuestro artículo específico: Duplicada: Google ha elegido una versión canónica diferente a la del usuario.
Excluida por la etiqueta noindex
La etiqueta <meta name="robots" content="noindex"> le indica explícitamente a Google que no incluya esa página en su índice. Cuando este motivo aparece en el informe, lo primero que debes comprobar es si esa directiva la pusiste tú de forma consciente o si está ahí por error.
En WordPress existe una opción en la configuración de lectura que dice «Solicitar a los motores de búsqueda que no indexen este sitio». Si esa casilla está marcada, toda tu web estará bloqueada para Google. También puede ocurrir que un plugin de SEO haya aplicado el noindex de forma masiva en alguna actualización o cambio de configuración. Hemos visto este error en más de una web de clientes con un impacto devastador en el tráfico orgánico.
Para resolverlo, localiza la etiqueta en el código fuente de las páginas afectadas, elimínala si no es intencionada y solicita la reindexación desde la herramienta de inspección de URL.
Bloqueada por robots.txt
El archivo robots.txt indica a los robots de los buscadores qué partes de tu web pueden rastrear y cuáles no. Cuando Google identifica que no puede acceder a una URL porque el robots.txt lo impide, lo registra bajo este motivo.
La clave está en diferenciar si el bloqueo es intencionado o accidental. Bloquear rutas como /wp-admin/ es correcto y necesario. Sin embargo, bloquear inadvertidamente /wp-content/ puede impedir que Google acceda a tus imágenes, archivos CSS o JavaScript, lo que deteriora el rastreo y la renderización de tus páginas.
Para revisarlo, accede al archivo robots.txt de tu dominio añadiendo /robots.txt al final de tu URL y analiza cada regla Disallow. La herramienta de inspección de robots.txt de Search Console también te permite comprobar si una URL concreta está bloqueada o no.
Página alternativa con etiqueta canónica adecuada
Este estado no es un error, sino una confirmación de que todo funciona correctamente. Significa que Google ha detectado una página con una etiqueta canonical que apunta a otra URL y está respetando esa indicación. La URL marcada como canónica es la que está indexada; la alternativa, intencionadamente excluida.
Aparece en el informe simplemente porque Google registra todas las URLs que encuentra, incluidas las que has decidido excluir de forma voluntaria. No requiere ninguna acción a menos que compruebes que el canonical está mal configurado y apunta a una URL incorrecta.
Duplicada: el usuario no ha indicado ninguna versión canónica
Este caso ocurre cuando Google detecta dos o más páginas con contenido muy similar o idéntico y ninguna tiene una etiqueta canonical. El algoritmo no sabe cuál de las dos versiones es la que debes indexar y puede decidir no indexar ninguna, o elegir la que considera más relevante de forma arbitraria, que puede no ser la que tú preferirías posicionar.
La solución pasa por identificar cuál es la URL principal de cada grupo de páginas duplicadas e implementar la etiqueta canonical correspondiente. Además, conviene revisar el enlazado interno para asegurarse de que todos los enlaces apuntan consistentemente a la URL preferida.
Soft 404 o error suave
Un soft 404 ocurre cuando una página devuelve un código HTTP 200 (todo correcto) pero su contenido equivale a un mensaje de «página no encontrada» o similar. Google detecta esta incoherencia y decide no indexar esa URL.
Es frecuente en tiendas online cuando un producto se agota y la página muestra un contenido vacío o un mensaje genérico, y también en webs que generan URLs dinámicas con parámetros que no devuelven contenido real. La solución más adecuada depende del caso: si la página ya no tiene razón de existir, lo correcto es devolver un código 404 o 410 real o implementar una redirección 301 hacia una página relacionada.
Error del servidor (5xx)
Cuando el servidor devuelve un error de tipo 5xx, significa que no pudo procesar la solicitud de Googlebot. Puede deberse a una sobrecarga puntual del servidor, a un problema con el hosting o a un error de configuración más profundo. Si este motivo aparece de forma recurrente y afecta a muchas URLs, conviene revisar la estabilidad y los recursos del servidor con tu proveedor de alojamiento.
Redirección errónea o cadena de redirecciones
Las redirecciones mal implementadas, los bucles de redirección o las cadenas demasiado largas pueden impedir que Google llegue a la URL final. Lo ideal es que todas las redirecciones sean directas, de origen a destino en un solo salto, y que utilicen el código 301 para traspasar correctamente la autoridad SEO acumulada.
Cómo actuar ante este aviso paso a paso 🔍
- Primero, accede al informe de páginas en Search Console y revisa qué motivos específicos están apareciendo y cuántas URLs afecta cada uno. No todos tienen la misma gravedad ni requieren la misma urgencia.
- Después, filtra por fuente. Si el motivo tiene como fuente «Sitio web», tienes control directo y puedes corregirlo. Si la fuente es «Sistemas de Google», la solución requiere mejorar la calidad del contenido o la estructura interna del sitio.
- A continuación, usa la herramienta de inspección de URL para analizar páginas concretas. Introduce la URL afectada y Search Console te mostrará exactamente qué ve Google cuando la rastrea, si está indexada o no y cuál es el motivo específico.
- Luego, prioriza los errores que afectan a tus páginas estratégicas. No tiene el mismo impacto que no esté indexada una página de política de privacidad que un artículo de blog o una ficha de servicio en la que has invertido esfuerzo de optimización.
- Finalmente, corrige, valida y solicita la reindexación desde la herramienta de inspección de URL para cada página corregida. Ten en cuenta que Google no garantiza tiempos de indexación concretos: el proceso puede tardar desde unos días hasta varias semanas en función de la autoridad del dominio y la frecuencia de rastreo.
Problemas de indexación e inteligencia artificial: una relación directa 🤖
Un aspecto que cada vez cobra más peso en cualquier estrategia de posicionamiento es el impacto de los problemas de indexación en la visibilidad dentro de los nuevos buscadores y modelos de IA. Herramientas como ChatGPT, Gemini o Perplexity rastrean la web para generar sus respuestas, y los modelos de lenguaje priorizan contenido que está correctamente indexado y es accesible de forma clara.
Si una página tiene problemas de indexación en Google, las probabilidades de que sea citada en respuestas generadas por IA se reducen drásticamente. Del mismo modo, las AI Overviews de Google priorizan fuentes que el propio buscador considera fiables e indexables. Por eso, resolver los problemas de indexación que detecta Search Console ya no es solo una tarea técnica: es también una palanca de visibilidad en el ecosistema de búsqueda basado en inteligencia artificial.